 Miguel Escobar Publicada marzo 26, 2019
Miguel Escobar Publicada marzo 26, 2019 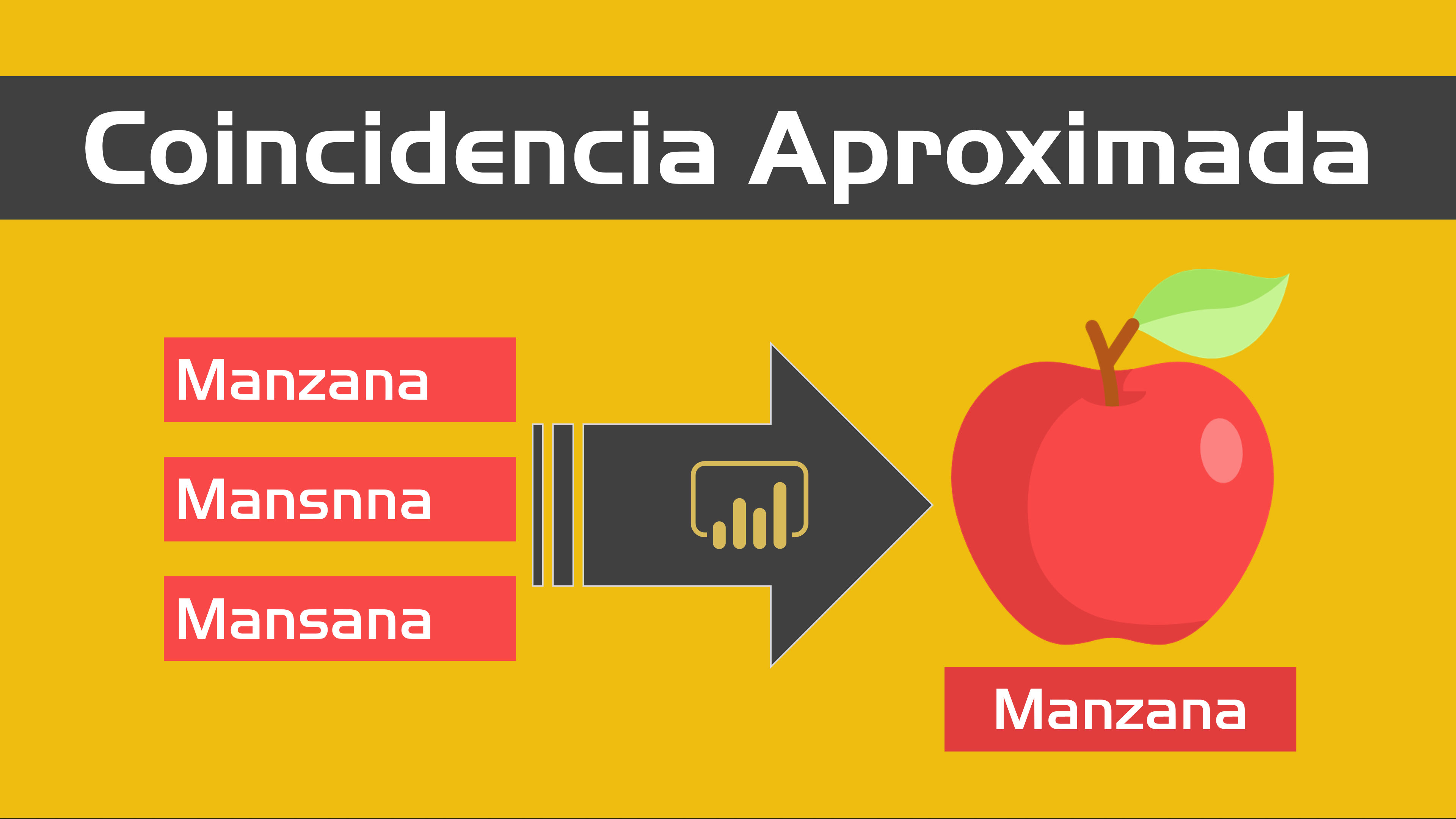
¡Una publicación muy esperada! La función de vista previa de la coincidencia aproximada se agregó a Power BI Desktop hace MESES y aquí está mi opinión sobre ella.
¿Qué es la coincidencia aproximada (fuzzy matching)? En resumen, es un algoritmo para la concordancia aproximada de secuencias.
¿Por qué es importante?Hasta septiembre del año pasado, Power BI / Power Query solo nos daba la opción (de forma nativa) de realizar operaciones de combinación similares a un VLOOKUP (FALSO) donde solo podemos realizar coincidencias exactas. Eso ha cambiado y ahora podemos realizar coincidencias «cercanas» o «aproximadas» gracias a la coincidencia aproximada (fuzzy matching).
¿Qué puedo hacer con ella? ¡Déjame darte un ejemplo práctico de algo que recientemente tuve que hacer!
El Escenario: Una Encuesta
Imagina que recientemente enviamos una encuesta bastante interesante en nuestra oficina. Básicamente, una encuesta sencilla en la que solo teníamos una pregunta principal:
¿Cuál es tu fruta favorita?
Lamentablemente, no teníamos ningún tipo de validación, por lo que las personas no podían seleccionar de una lista ni tenían a disposición algún tipo de relleno automático, por lo que ese campo era completamente libre.
Esto significaba que tendríamos que hacer algo de limpieza de datos para entenderlos realmente.
Cuando recibimos todas las respuestas de nuestra encuesta, la exportación se veía así:

Así que puedes imaginar que cuando intentamos crear un gráfico a partir de ellas, no nos proporcionó la información que esperábamos:

Como puedes ver, parece que tenemos algunos problemas con la calidad de los datos, lo que significa que necesitamos limpiarlos y este es un escenario perfecto para una combinación con la coincidencia aproximada (o fuzzy matching)
Implementando la coincidencia aproximada (fuzzy matching)
Antes de seguir adelante, tenemos que fijarnos una meta. Nuestro objetivo es llegar a la siguiente tabla:

Donde crearíamos esta nueva columna llamada Fruit para que podamos usarla como el eje de nuestro gráfico:

Para que esto suceda, usaremos una coincidencia aproximada, pero incluso antes de intentar realizar la operación de combinación, necesitamos tener otra tabla además de nuestra tabla de la encuesta original.
Respuestas válidas o tabla de diccionario
Necesitamos crear o tener una tabla con los valores que deben ser «válidos». En otras palabras, podríamos decir que esta es una tabla con los valores que se escribieron correctamente O es la tabla de diccionario y estamos tratando de averiguar si alguno de los valores de los resultados de la encuesta es similar a la tabla de las respuestas válidas o del diccionario.
Vamos a manejar una tabla corta como ejemplo, pero nuestra tabla se verá así:

al tener esa tabla ya lista, ahora podemos pasar a la siguiente fase que es realizar la operación de combinación con la coincidencia aproximada.
Operación de combinación o fusión con la coincidencia aproximada (fuzzy matching)
En el caso de que la operación de combinación o unir en Power BI / Power Query se nueva para ti, te recomiendo que consultes esta página sobre qué es y qué pueden hacer por ti.
Con las dos tablas mencionadas anteriormente (nuestros resultados de la encuesta y la tabla de diccionario) dentro del editor de Power Query, podemos realizar una nueva operación de combinación como una nueva consulta tomando los resultados de la encuesta como base:

y en esa ventana de Combinación, marcamos la casilla de verificación «Usar coincidencia aproximada para realizar la combinación» o «Use fuzzy matching to perform the merge”.
Simplemente hacemos clic en Aceptar y el resultado se verá así:

y lo siguiente que debemos hacer es simplemente expandir los valores de la Tabla dentro de la Columna Diccionario haciendo clic en el icono que tiene las dos flechas en direcciones separadas. El resultado de esto se verá así:

¡Se ve bien a primera vista! Pero nos falta el valor de «Coco», que debería ser «Coconut».
Sería fantástico si pudiéramos saber cómo funciona el algoritmo de la coincidencia aproximada, pero eso solo lo sabe Microsoft, pero hay algunas opciones aproximadas con las que podemos jugar para ver si podemos obtener mejores resultados.
Opciones de coincidencia aproximada (fuzzy matching)
Regresemos al paso de la fuente de esa consulta y hagamos clic en el ícono del engranaje para que podamos modificar la operación de Combinación. Probablemente hayas notado un ícono de expandir junto a las «Opciones de coincidencia aproximada» en una de las capturas de pantalla anteriores. Cuando haces clic en él, esto es lo que obtienes:

Vamos a hacer un resumen de las opciones que vemos y lo que hacen:
- Umbral de similitud (Similarity treshold) –puede ser un número de 0 a 1, que se traduce en la similitud con la que deben coincidir las cadenas de caracteres para que se muestren en la tabla de resultados. De forma predeterminada, está configurado en 0,8, que es simplemente una forma de decir que deben tener el 80% de similitud.
- Ignorar caso (Ignore case) – si está marcado, entonces el algoritmo ignorará si las letras están en mayúsculas o en minúsculas y no tomará en cuenta el caso.
- Coincidir combinando partes del texto –probablemente viste el ejemplo de «watermelon», que se escribió incorrectamente como «water melon». Lo que hace esta opción es que, en caso de que haya un espacio entre las cadenas de caracteres, combinará ambas cadenas de caracteres en una sola. Si esto no sucediera, entonces el valor se habría fusionado en «Melon» o «Water», pero como está habilitado, terminó siendo «Watermelon».
- Número máximo de coincidencias –en algunos casos, es posible que desees limitar el número de coincidencias que obtienes según el «umbral de similitud» que hayas definido. Esta es la opción donde puedes definir cuántas coincidencias deseas, que pueden ser un número de 1 a un número REALMENTE alto (2147483647)
Después de jugar con estas opciones, terminé con esta configuración:

pero todavía no pude obtener el resultado que esperaba para el valor «Coco». Todavía me estaba dando un nulo.
Y aquí es donde entra la última opción, la tabla de transformación.
Tabla de transformación
Imagina un escenario en el que simplemente no hay manera de hacer una «coincidencia cercana» y necesitas de alguna manera decirle al sistema de manera explícita que quieres que «Coco» se refiera a «Coconut». Aquí es donde entra en juego la tabla de transformación.
Es como una especie de tabla de traducción, o también podría considerarse como una tabla de mapeo.
Esta tabla tiene algunos requisitos, pero son bastante sencillos y son que necesita 1 columna con el nombre de From y otra con el nombre de To. No importa si estás en la versión en español del Editor de Power Query, esos DEBEN ser los nombres de las columnas, de lo contrario esto no funcionará.
Así es como se ve mi tabla Transformar:

Esencialmente, la coincidencia aproximada buscará los valores de la columna «From» y los reemplazará con el valor que vemos en la columna «To». Esta es una coincidencia explícita o «Mapeo».
A continuación, suministramos esa tabla a las opciones de coincidencia aproximada así:

¡y este parece algo prometedor, ya que muestra que hay 10 de 10 coincidencias!
Cuando vuelvo al último paso, veo esto:

¡Exactamente lo que estábamos buscando!
En este punto, podemos simplemente cerrar y cargar y crear el gráfico que necesitamos.
Opciones avanzadas de coincidencia aproximada (Fuzzy Matching)
Si bien podemos obtener casi todo lo que necesitamos a través de la interfaz del usuario, hay algunas gemas ocultas dentro del código que usamos.
Esta nueva experiencia utiliza una nueva función con el nombre de: Table.FuzzyNestedJoin
Aquí está la documentación que encontramos dentro de esa función:

Ya hemos visto la mayoría de ellas, excepto las 2 que están resaltadas.
Esto es lo que dice el resto de la documentación:

El que más me llama la atención es «ConcurrentRequests», lo que significa que podemos definir cuántos subprocesos puede utilizar esta operación en caso de que necesitemos más poder.
No he tenido una situación en la que haya necesitado definir la cultura todavía, pero puedo ver que esto podría ser beneficioso para algo como una cadena de caracteres muy larga para una coincidencia aproximada.
Me encantaría saber si alguna vez has intentado usar alguna de estas opciones avanzadas.





Hola Miguel, estoy utilizando esta opción, pero lo hacia sin la tabla, por lo cual aun tenia algunos datos que no me coincidían, pero con la tabla especifica ya tengo el 100%, he ido extrayendo estos casos particulares y tengo una tabla que adicionare para que pueda hacerme la conciencia. Gran articulo, muchas gracias. .:)
Hola, Osiel, ¿cómo usas esta opción sin la tabla diccionario? Es lo que estoy tratando de hacer, pero no encuentro cómo.
Hola Miguel, la solucion es de gran utilidad, solo una duda tambien funciona para la cadena de numeros enterios?
Hola Diego! Realmente esto sólo aplica para cadenas de texto, por lo que tendrías que transformar tus números de tipo de dato numérico a tezto
Buenos dias Miguel, la herramienta es de mucha utilidad para el trabajo que realizo diariamente, solo tengo una duda se puede mostrar el valor porcentual de coincidencia en una columna nueva, esto me seria de mucha ayuda al filtrar las coincidencias de menor valor. Si no se puede tenes alguna idea de como realizarlo?
Hola! Realmente desconozco, pero si encuentras algo no te olvides de compartirlo!
Hola Miguel, quería saber si existe la manera de habilitar el checkbox, dado que cuando quiero combinar no me aparece automáticamente la opción para habilitar la coincidencia aproximada debajo del tipo de combinación
Hola!
¿Qué versión de Power BI o Excel estás utilizando? En las versiones más actuales de ambas la característica viene habilitada de manera automática.