 Miguel Escobar Publicada julio 30, 2019
Miguel Escobar Publicada julio 30, 2019 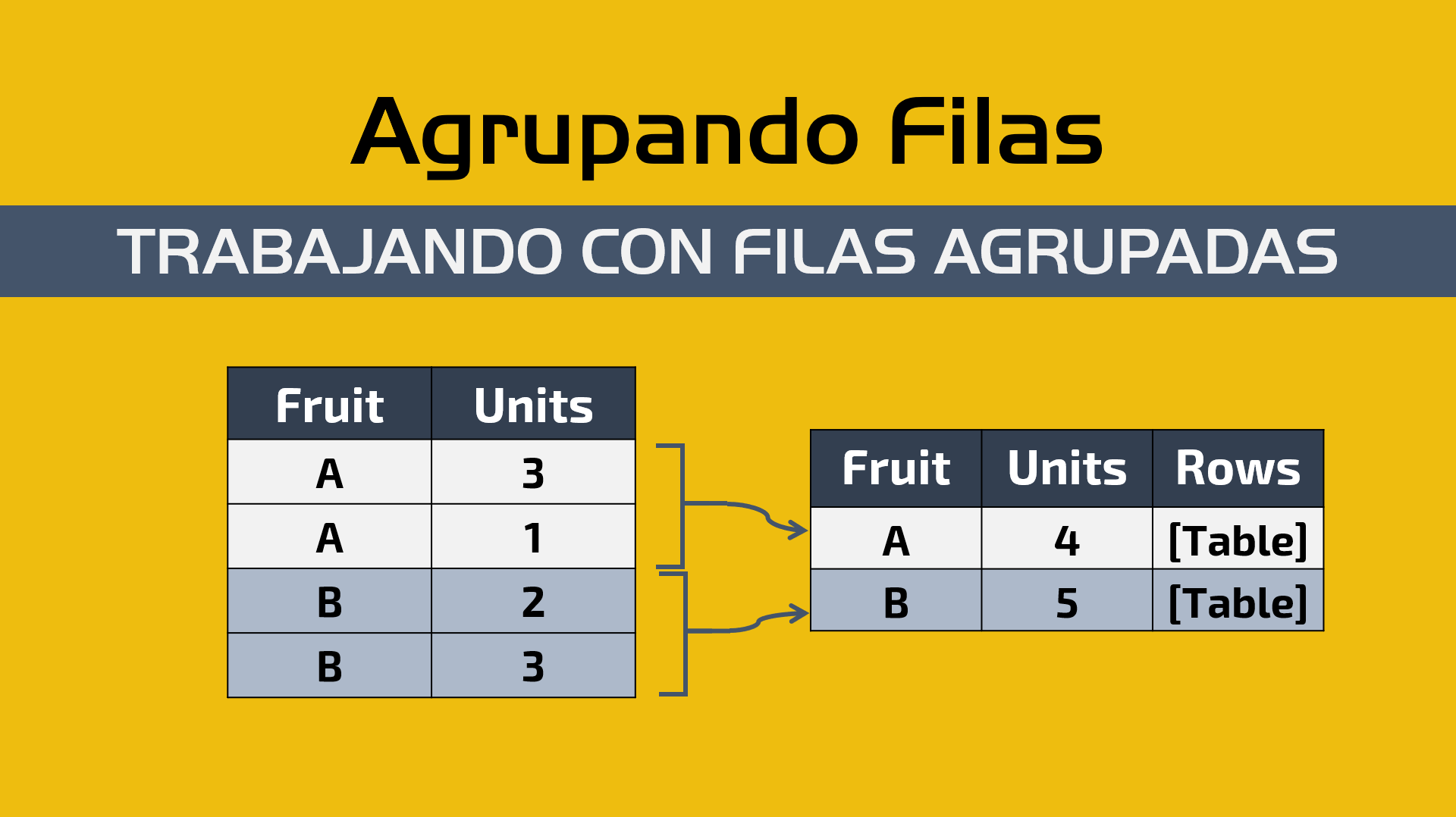
Desde sus orígenes, Power Query / Power BI ha tenido esta función llamada Group By (Agrupar por) y puedes verla en el menú principal y el de Transformar bajo el siguiente icono:

No es un ícono realmente descriptivo. No me da tanta información más que otra cosa depende de otra cosa (a través de esa línea).
¿Qué hace Group By? ¿Cuándo debo usar Group By?
En resumen, el Group By operación dentro de Power BI / Power Query intenta hacer 2 cosas:
- Resumir sus datos –obtendrás tu tabla resumida solo por las columnas que selecciones. Esto es asombroso si estás tratando de deshacerte de los duplicados o de verificar dónde tienes duplicados.
- Provide Aggregations or Non aggregated Data – imagina estas nuevas columnas que proporcionarán agregaciones como suma, máximo, mínimo, promedio de una columna y, en algunos casos, otras columnas que no harán ninguna agregación y solo mostrarán filas agrupadas como tabla.
Es recomendable usar la funcionalidad Group By (Agrupar por) cada vez que necesites hacer cualquier cosa que tenga que ver con agrupar filas de una tabla en función de los valores que tengan en sus campos.
Vayamos directamente a los ejemplos del mundo real de cuándo querrías usar este grupo por función y lo que trae a la mesa.
Asegúrese de hacer clic en el siguiente botón para descargar el archivo de muestra y también las soluciones.
1. Resumir datos
Conjunto de datos Original: tenemos datos que tienen el aspecto de un informe con todos los campos en lugar de algo que usaríamos dentro de un modelo de datos Power BI / PowerPivot Data Model.
![SNAGHTMLa9353dd[4]](https://thepoweruser.com/wp-content/uploads/2019/07/SNAGHTMLa9353dd4.png "SNAGHTMLa9353dd[4]")
Objetivo: normalizar nuestro conjunto de datos y crear una tabla de dimensiones de clientes para nuestro modelo de datos de Power BI. Tendríamos una tabla de hechos con solo la clave del cliente y otra tabla con todos los campos para los clientes.

¿Cómo agrupar filas con Power BI / Power Query para esto?
Aquí está el paso a paso de lo que tenemos que hacer:
- Dirígete a la hoja 1 o, si usas Power BI Desktop, conéctate a la tabla dentro de la hoja «1» del libro de muestra.
- Nombra esta consulta «Original»
- Crea una referencia a la consulta «Original» dos veces y nombra una de esas referencias «Dim_Customers» y la otra «Fact_Sales»
Ahora que tenemos estas 3 consultas. El objetivo es cargar solo «Dim_Customers» y «Fact_Sales» a nuestro modelo de datos.
En un sentido más técnico, estamos tratando con lo que se llama una tabla desnormalizada y necesitamos normalizarla (reducir la redundancia de datos) básicamente moviendo la mayoría de esos campos a una nueva tabla y manteniendo solo un campo que actuará como el «Clave» para nuestros clientes. Resulta que llamo a ese campo «CustomerKey» para que sea más fácil para este ejemplo, pero en el mundo real podría llamarse de otra manera.
Creando una tabla de dimensiones para clientes
Vamos a trabajar en esa consulta «Dim_Customers». En la tabla original verás que he marcado algunas columnas con un color amarillo. Hice esto porque todos esos campos se refieren a un solo objeto o elemento y se refiere al cliente.
Haz clic en el icono Group By y luego en la ventana Group By selecciona la opción Avanzada. Luego, para los campos Group By, selecciona CustomerKey, Customer, Category, Group, Primary Contact como se muestra en la siguiente imagen:

El resto lo puedes dejar por defecto.
El resultado será una tabla resumida sin duplicados para nuestros campos de clientes y una nueva columna llamada «Count» que solo podemos eliminar. Después de eliminar esa columna de «Count», terminarás con tu tabla exactamente como la necesitas:

Normalizando nuestra tabla de hechos
Nuestro objetivo con esta consulta es super simple. Eliminemos todos los campos que tienen algo que ver con la tabla de dimensiones recién creada para los clientes, pero mantengamos el campo CustomerKey para que podamos crear la relación entre las tablas.
De una manera más visual, eliminemos los campos resaltados en rojo en la siguiente imagen:

Simplemente selecciona esos campos en rojo (Customer, Category, Group, and Primary Contact) y luego haz clic con el botón derecho en cualquiera de esas columnas y selecciona la opción que dice » Remove Columns»:

El resultado de esa operación te dará una tabla que se ve así:

y con esto tienes tu tabla de Fact_Sales lista para ser cargada en tu Data Model.
Construyendo nuestro modelo de datos y creando el informe
Si está en Power BI Desktop, puedes seleccionar tus consultas en el panel «Queries» y asegurarte de que solo se carguen los Fact_Sales y Dim_Customers en su modelo de datos, pero dentro de Power Query para Excel, primero debes cargar tus consultas como “connection only” y luego cárgalos en su Data Model.
La clave principal aquí es que necesitas las dos tablas / consultas que acabamos de crear en tu Modelo de Datos y luego, dentro de tu Modelo de Datos, puedes crear una relación entre esas 2 tablas utilizando el campo Clave de cliente (CustomerKey) de ambas tablas. Simplemente puedes arrastrar un campo de una tabla al campo de la otra tabla utilizando la vista Diagrama y la aplicación creará la relación para ti. El resultado final se verá así:

Con esto fuera del camino, puedes concentrarte en crear tu informe. En mi caso, terminé creando este informe dentro de Excel, que muestra los 10 principales clientes por orden total de cada grupo de clientes

Consideraciones finales
La principal conclusión aquí es que este principio puede usarse para cualquier dimensión o cualquier tipo de escenario de normalización que se pueda imaginar.
Hay otra forma válida de hacer esto y es simplemente manteniendo las columnas que necesitas y luego elimina los duplicados de esas columnas. De nuevo, completamente válido, pero es una cuestión de preferencia en este punto.
2. Resumir datos y agregar agregaciones basadas en filas agrupadas

Conjunto de datos original: conjunto de datos similar al del primer escenario, pero esta vez tiene más campos
Objetivo: crear un informe de alto nivel que nos ofrezca un resumen del desempeño del mes actual
¿Cómo agrupar filas y agregar agregaciones con Power BI / Power Query?
Al igual que en el primer caso, necesitamos obtener los datos que están en la hoja con el nombre «2». El nombre de esta tabla es «Example_2» y todo lo que necesitas hacer es conectarte a ella y notarás que se trata de un informe con 18 columnas y muchas filas.
Agarrando los datos del mes actual
Lo primero que debemos hacer es agregar un filtro a nuestra columna OrderDate para que solo tomemos en consideración los datos del mes actual. Creé este archivo de muestra para que siempre obtengas un conjunto de fechas en función de tu hora actual, por lo que siempre debería de funcionar.
El filtro que queremos hacer está dentro de los Filtros de Date/Time, Month y luego «This Month» (este mes):

Eso nos asegurará de que solo tomamos en consideración los pedidos del mes actual.
Una vez hecho esto, podemos seguir adelante con la operación del Group By (Agrupar por).
Creando un informe de resumen con Group By (Agrupar por)
Ahora viene la parte donde puedes presionar el botón Group By (Agrupar por) y hacer que se vea como se muestra en la siguiente imagen:

Para resumir lo que estamos tratando de hacer:
- Queremos Agrupar todos los pedidos por Ciudad (City)
- Basado en esa agrupación, queremos conseguir
- Las órdenes totales (haciendo un recuento de todas las filas que coinciden con la ciudad)
- La cantidad total de unidades vendidas
- Los ingresos totales
Luego hice una clasificación rápida basada en el Ingreso Total y el resultado de esa operación nos da esto:

Consideraciones finales
Veo que esta característica se usa cada vez más en Microsoft Flow, donde las personas se conectan a su base de datos de SQL Server para crear extractos que luego se envían automáticamente como una tabla HTML (un informe final) a un ejecutivo que requiere ver estos datos en su propio programa o basado en alertas para ver detalles específicos de un conjunto específico de registros que se agrupan según las condiciones (usando Group By).
¡Extremadamente útil! Si necesitas resumir tus datos sin la necesidad de interactividad, como en las tablas dinámicas, entonces esto podría ser todo lo que necesitas.
3. Resume los datos, agrega agregaciones y expande filas agrupadas

Conjunto de datos original: tenemos un refrigerador industrial donde hacemos envejecimiento seco a nuestras carnes (dry aging). Dentro de este refrigerador tenemos un sensor de temperatura IoT (Internet of Things). Registra la temperatura cada minuto del día y este es el conjunto de datos de un solo día.
Objetivo: Queremos comparar el promedio del día con cada minuto y averiguar los minutos en que la temperatura estuvo 5% por encima o por debajo del promedio para investigar más adelante.

¿Cómo agrupar filas y agregar una columna de no agregación con Power BI / Power Query?
Este es un excelente ejemplo para mostrar algunas de las gemas ocultas cuando se usa la función Group By.
Como siempre, tenemos que ir a la tabla para este caso que está dentro de la Hoja # 3 y cargar esos datos en Power Query.
El clic exacto que debemos tomar es el de «Group By» y luego necesitamos tener nuestro Grupo By (Agrupar por) como se muestra a continuación:

Observa que el único Group By por campo es el ID del refrigerador (Fridge ID) y luego para las New Columns tenemos uno que hace el Promedio (Average) de la Columna de Temperatura o Temperature (que tiene las temperaturas en Fahrenheit) y luego tenemos otra columna que llamamos «Rows» que hace una operación «All Rows «.
Después de pulsar OK, obtenemos esto:

¿Cómo Trabajar con filas agrupadas en Power BI / Power Query?
Presta mucha atención a la columna «Rows» que contiene una tabla. Esa tabla contiene TODAS las filas de la tabla anterior. Lo que debemos hacer es hacer clic en el ícono que se encuentra en la parte superior (donde parecen dos flechas que van en direcciones opuestas) y luego hacemos una operación que se llama » Expand Operation «, donde seleccionamos las columnas que queremos expandir, que son todas excepto Fridge ID y esa interacción se verá así:

y una vez que se haya aplicado, tendremos una tabla similar a la inicial, pero con el «Daily Temp Avaerage» que es la temperatura promedio del día:

Después de esto, podemos hacer nuestra magia con una columna personalizada (ir al menú Add Column y seleccionar Custom Column) y agregar la fórmula simple que se muestra a continuación:

Luego nos dirigimos hacia más operaciones para obtener la diferencia entre estas 2 columnas, pero lo que terminé haciendo fue simplemente usando esta nueva columna «Difference», luego la transformé en un valor absoluto y la filtré para obtener solo los valores que son superiores a 0.05 (o 5%), por lo que podría terminar con la siguiente salida:

Estos son todos los minutos en los que la temperatura estuvo 5% por encima o por debajo de la media, que fue de alrededor de 34 grados F.
Solo ten en cuenta que debes mantener tu refrigerador seco a una temperatura de entre 34 y 38 F.
Consideraciones finales
¿Qué es tan sorprendente de lo que acabamos de hacer? La clave de todo es la forma en que podemos usar las » grouped rows » para volver a expandir esas filas y usar el promedio de todo el conjunto de datos contra cada fila. Podrías haber hecho varias columnas agregadas como MAX, MIN y otras, pero para este caso solo tuve el promedio, pero puedes aprovechar mucho más que eso y también funciona cuando tienes varias instancias de Group By. Si tuviera, por ejemplo, otro refrigerador, entonces la técnica seguirá funcionando, no tendría que cambiar nada de la consulta en sí. Simplemente funcionará.
En el siguiente ejemplo, te mostraré cómo ir aún más lejos y hacer un «aprovechamiento» más avanzado de las tablas de «Grouped Rows» o «Filas Agrupadas».
4. Usar funciones M contra filas agrupadas

Conjunto de datos original: tenemos un informe de las ventas para el año 2018 por cliente, región. y país.
Objetivo: queremos resumir este informe para que solo tenga los 3 principales clientes, según el campo de ingresos.

Este escenario no es tan fácil como el resto. No es tan complejo como podría pensarse tampoco. Se trata de tener una buena comprensión de cómo trabajar con las «Filas Agrupadas» que se encuentran en esa columna con los valores de la tabla que vimos en el ejemplo anterior.
¿Cómo agrupar filas, agregar una columna de agregación y agregar una columna de no agregación con Power BI / Power Query?
Como siempre, tenemos que ir a la tabla para este caso que está dentro de la Hoja # 4 y cargar esos datos en Power Query.
La tabla que estamos buscando se llama «Example_4» y una vez que obtengas los datos dentro de Power Query / Power BI, crea una referencia de esa consulta. Cambia el nombre de esta nueva consulta para que sea «Output «.
El paso a paso es sencillo y directo. En esta nueva consulta, presione el botón Agrupar por, agrupe por «Región» y agregue una nueva columna con la operación » All Rows » como se muestra a continuación:

y el resultado de esto debe verse así:

Nota lo que hice. Hice clic en la hoja blanca al lado del valor de «Table» y obtuve una vista previa del contenido de esa tabla en una ventana de vista previa de valor justo debajo. ¿Cuán genial es eso?
¿Cómo trabajar con filas agrupadas? ¿Cómo podemos ordenar, clasificar e indexar estas filas / registros con Power BI / Power Query?
Bien, revisemos nuestro objetivo. Lo que necesitamos es extraer los 3 principales clientes de cada región en función del valor que tienen para la columna Total ordenada en orden descendente. ¿Notaste algo especial sobre nuestra tabla? Sí, no está ordenado correctamente
Entonces, lo que tenemos que hacer es:
- Ordenar los datos por la Columna Total
- Mantener solo las 3 filas superiores
- Agregar un índice o clasificación
- Expandir la tabla
- ¡Disfruta de nuestro informe!
Vayamos con cada uno ahora
Ordenar los datos por la Columna Total
Dado que los datos que necesitamos están dentro de una tabla, necesitamos usar las funciones de la tabla contra ellos. Para hacer una ordenación, la función de tabla que necesitamos es Table.Sort y la usaríamos en una columna personalizada como esta:

La función Table.Sort requiere una Tabla como su primer parámetro y luego una lista del orden de clasificación y el tipo de clasificación que se aplicará a cada columna. Así es como terminamos con la fórmula:
Table.Sort([Grouped],{{«Total», Order.Descending}})
Mantener solo las 3 primeras filas
Tenemos todas tablas ordenadas en esa columna. Ahora podemos simplemente mantener las primeras 3 filas de cada tabla y eliminar el resto de filas. Para hacer eso usamos una función llamada Table.FirstN. Así es como se ve cuando lo uso para una columna personalizada:

Comprueba esto, en lugar de usar la tabla de la columna » Grouping «, ahora estoy usando la columna » Sorting » que tiene la tabla ordenada. Esto creará una nueva columna con el nombre «Keep Top 3» usando esta fórmula:
Table.FirstN([Sorting],3)
Agregar un índice o clasificación
Ahora pasamos a la parte final de enriquecer esas tablas de filas agrupadas agregando una nueva columna a cada tabla para indicar el orden o rango de cada fila usando un Índice. Esta vez usaremos la función Table.AddIndexColumn de esta manera:

Y mira lo bien que se ve nuestra tabla en la ventana de vista previa en la parte inferior izquierda de la imagen de arriba.
Expandir la tabla
Todo lo que tenemos que hacer ahora es simplemente deshacernos de las columnas “Grouped”, “Sorting”, y “Keep Top 3” y obtendremos una consulta simplificada como esta:

y por último, pero no menos importante, expandimos esta columna de la tabla y obtenemos el informe que estamos buscando:

¡Disfruta del informe!
Antes de que podamos disfrutar de nuestro informe, debo advertirte sobre algo realmente específico para Power Query.
Cuando hacemos una operación de clasificación o algunas operaciones que requieren conocer la posición de una fila específica en una tabla, se recomienda que almacenes la tabla en búfer antes de hacerlo.
¿Qué es el buffering? te podrías preguntar, La idea de los términos de Buffering en Power Query es que almacenes tus datos en la memoria caché, de modo que solo necesitas leerlos una vez y aplicar las transformaciones sobre los datos almacenados en caché. De lo contrario, la clasificación podría no ajustarse / mantenerse después de realizar la operación de expansión o algún otro tipo de operación.
Hay algunas maneras de aplicar este almacenamiento en búfer. Puedes aplicarlo directamente en la tabla «Grouped Rows» o también puedes hacerlo en el primer paso de esta consulta para que podamos trabajar con los datos almacenados en caché desde el principio. Modifiquemos la columna » Sorting » para que tenga la siguiente fórmula:

Consideraciones finales
Este es el verdadero poder detrás de Power Query. Cómo dentro de una tabla puede tener otra columna con valores de tabla y aplicar funciones de tabla con ellos y diseñar algunas formas realmente inteligentes para abordar escenarios. Esta es una forma de pensar completamente nueva que no encuentra en Excel o DAX.
Una característica clave aquí es que, en lugar de crear tantas columnas, podríamos haber creado nuestra propia función personalizada y hacer todo en un solo paso. Puedes leer más sobre cómo puedes crear tu propia función personalizada desde cualquiera de estos artículos:
Conclusión
Hemos visto todas las posibilidades que Group By trae a la mesa. Cambia fundamentalmente la forma en que vemos y abordamos escenarios y esta es una de las razones por las que debemos dejar de abordar los escenarios en Power Query de la misma manera que lo haríamos en Excel.
Power Query se encuentra en un nivel completamente diferente, lo que nos hace sentir más como la película «Inception» debido a cómo puede trabajar con tantos niveles y nodos diferentes en una sola vista de los datos.

¡Asegúrate de hacerme saber tus comentarios sobre este tipo de publicación de blog más larga!





wow! genial, las ultimas me impresionaron, pense que en el caso 4 utilizarias un agrupar por cliente y obteniendo un maximo. No me lo esperaba fue genial!, gracias Miguel.
Hola,
Espero que todos estéis bien!!
Estoy intentando hacer el escenario 4, pero el sistema de ranking no acaba de ajustarse a lo que necesito :
Referencia FECHA USUARIO codigo
181197047 18/03/2020 Z1182587 7558612
181197047 18/03/2020 Z1182587 7689219
181197047 23/03/2020 Z5046010 7558612
A la hora de establecer el ranking, los ordena segun este listado del 1 al 3.
cuando lo que necesito es que el 1 y el 2 los considere 1 en el rankin puesto que tienen la misma referencia pero el código es distinto, y el 3 lo considere 2 en el ranking puesto que tiene el mismo codigo que el 1
Pero no se como hacerlo, no quiero los 3 primeros mejores, sino necesito conocer los registros únicos de cada referencia+codigo, no solo de cada referencia. En excel hacía un concatenar con la referencia y codigo, pero aquí no se como pueda hacerlo.¿Podéis ayudarme?
Gracias!!!!
Un saludo
Hola Carol!
Te recomiendo publicar tu escenario completo con lujo de detalles y archivos de ejemplo en el nuevo foro oficial de Micorosft para Power BI:
https://community.powerbi.com/t5/Translated-Spanish-Desktop/bd-p/pbi_spanish_desktop
Realmente este sitio de comentarios no es el mejor para poder dar soporte de esta clase, por lo que te recomiendo publicarlo en el foro.
Saludos!
Hola
Cuando se hacen estas relaciones dimension-hechos, se heredan los filtros…
Me explico…
Si yo tengo cada transacción como unaventa, y esta venta esta dividida por tipo de venta, yo me creo otra tabla con group by que lo que me hace es sumarme por venta cada categoria para agruparme cada venta, esto lo relaciono con la factura, entre la tabla dimension y hechos, pero cuando intento filtrar la categoria y los filtros que tenga con la dimensión la venta que tengo se mantiene estatica.