 Miguel Escobar Published January 19, 2020
Miguel Escobar Published January 19, 2020 
A few years ago I posted my first impressions on Power BI Incremental refresh that was only made available for Power BI Premium licenses.
The whole idea of incremental refresh is superb:
- You only refresh the data that you need – never again a FULL refresh needs to take place
- It makes your data source work less – so you won’t be hitting your data source with expensive queries that take a long time to execute and load
- Highway to insights! – you don’t have to wait those long hours just for your dataset to refresh
For the incremental to work as intended your data source has, to a certain degree, be able to handle query folding and most structured data sources like databases and OData are able to handle this with ease. How about files from a Folder either hosted locally or on SharePoint?
Note: Before you continue reading, I just wanted to say that this is an advanced topic on not only Power BI, but also on Power Query. If you or your company requires help setting this up, you can contact us at info@poweredsolutions.co for a quote on any type of assistance setting you up with the incremental refresh that works best for you.
The Scenario: Files in a SharePoint Folder
Imagine that we have Folder that has subfolders. One subfolder for every year and inside of those yearly folders we have the data for each of those years. It looks like this:
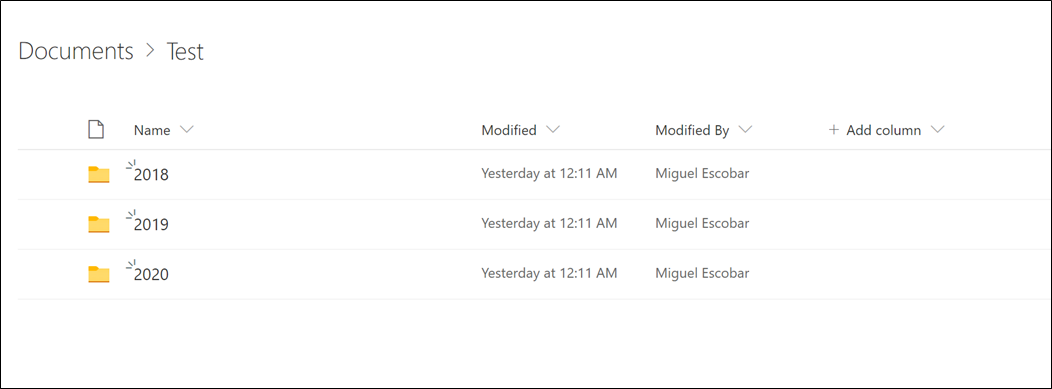
What we want to do is connect to this folder and then set up an incremental refresh logic, so we only refresh the data for the current year or, in other words, only get new data and keep the data from previous years to be intact and not be in the refresh process as it adds way too much processing / refresh time.
That means that while we’re in January of 2020, or any months in the year 2020 for that matter, we’ll only be refreshing the data for 2020. Once we get to the year 2021, we’ll start only refreshing the data for 2021 and the data for the year 2020 will be untouched.
In our case, we have Excel files in those folders, but we have SO many that it takes too much to refresh all of them.
The solution: taking advantage of Query Folding and Lazy Evaluation
Note: I highly recommend that you read these few articles if you intend to implement this on your own so you can understand what I’m doing:
What I need to do is quite straightforward. I need to use a Data Source function as a base and then create my custom function that will have the correct logic to drive the Incremental refresh with the RangeStart and RangeEnd parameters that the Power BI Incremental Refresh process requires.
We have 2 options in terms of Data Source functions. We can either use the “From Folder” (Folder.Files) data source function for local files or we can use the “SharePoint Files” (SharePoint.Files) for files hosted on SharePoint:
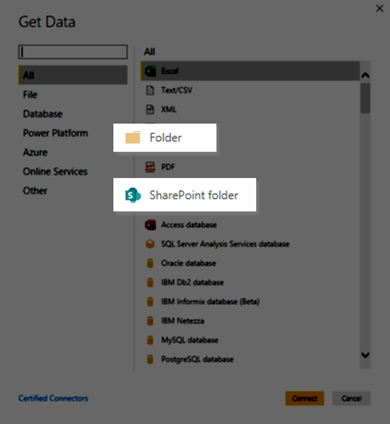
For this example, I’ll be using the SharePoint Folder connector / data source as I’m able to track what is going behind the scenes and if the incremental refresh is working correctly or not.
Step 1: Create the Custom Function
(StartDate as datetime, EndDate as datetime) =>
let
start = Number.From (Date.From(StartDate)),
end = Number.From(Date.From(EndDate))-1,
Years = List.Distinct( List.Transform( {start..end}, each Text.From( Date.Year(Date.From(_))))),
Source = SharePoint.Files("https://powerbipanama.sharepoint.com/sites/Services", [ApiVersion = 15]),
#"Filtered Rows" = Table.SelectRows(Source, each List.Contains( List.Transform( Years, (x)=> Text.Contains( [Folder Path],x) ), true)),
#"Added Custom" = Table.AddColumn(#"Filtered Rows", "Custom", each Excel.Workbook([Content], true)),
#"Removed Other Columns" = Table.SelectColumns(#"Added Custom",{"Custom"}),
#"Expanded Custom" = Table.ExpandTableColumn(#"Removed Other Columns", "Custom", {"Name", "Data", "Item", "Kind", "Hidden"}, {"Custom.Name", "Custom.Data", "Custom.Item", "Custom.Kind", "Custom.Hidden"}),
#"Custom Data" = Table.Combine(#"Expanded Custom"[Custom.Data]),
Schema = #table( type table [Date = date, ProductName = text, Territory = text, Sales = number, Code = text, Master Account = text], {})
in
try #"Custom Data" otherwise Schema
This is the custom function that I’ve created, but the part drives the magic is actually the Filtered Rows step:
#”Filtered Rows” = Table.SelectRows(Source, each List.Contains( List.Transform( Years, (x)=> Text.Contains( [Folder Path],x) ), true))
It is also super important that the names of the Folders are correctly entered and that the setup that we have for the naming convention of the folders is taken into consideration.
You could change this to your specific needs, and I’ve played with sub folders for the months and created other scenarios where there is an incremental refresh logic specifically for the months.
Again, you can customize this to your needs and all you need to know is a bit of the M language.
Step 2: Create the Parameters for Incremental Refresh
This part is quite straightforward. You just need to go through the Parameters window to add new parameters as I described in my first impressions article for the incremental refresh on Power BI.
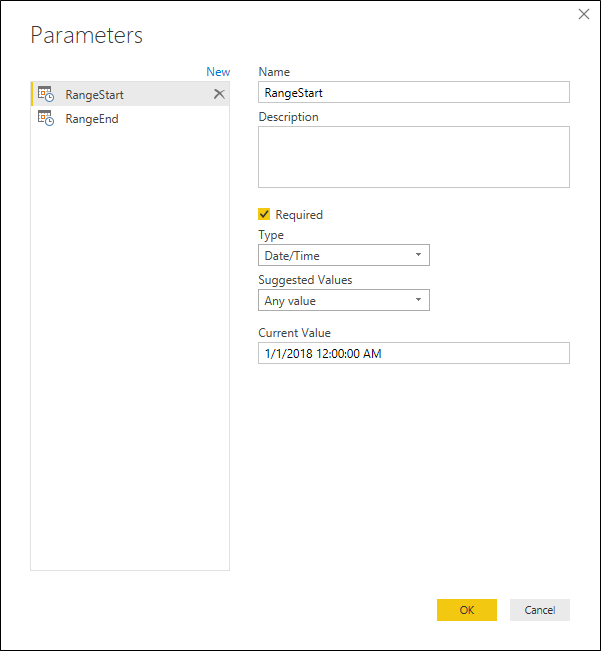
Step 3: Using your new Custom Function
Now you just need to invoke that custom function. In my case my Power Query window looks like this:
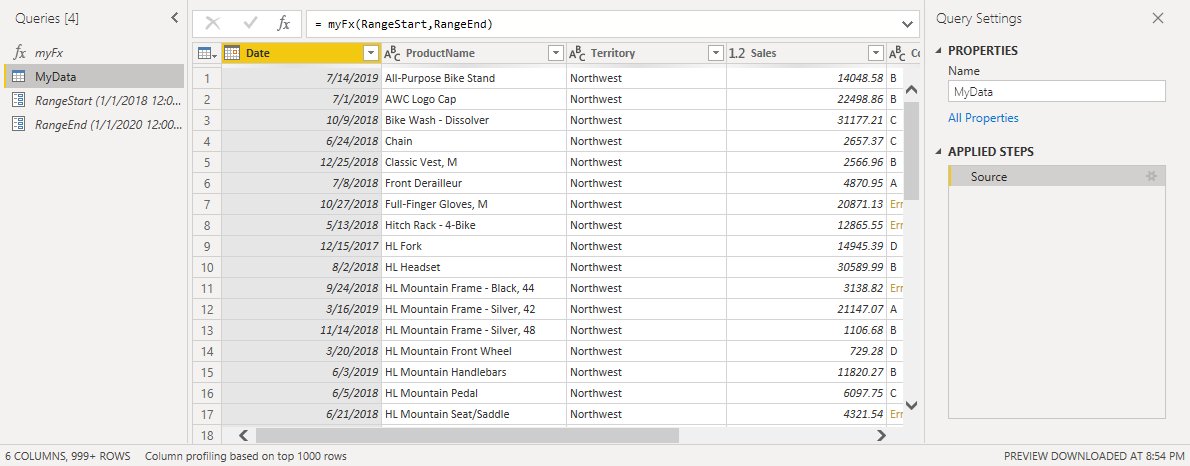
For the sake of testing, just to make sure that we’re only getting the data that we want, let’s change the RangeEnd parameter value to be 2/1/2019 (February 1st, 2019). Now go into the Tools Menu (enable it from the preview features if you don’t have it yet) and select the option for Diagnose Step:
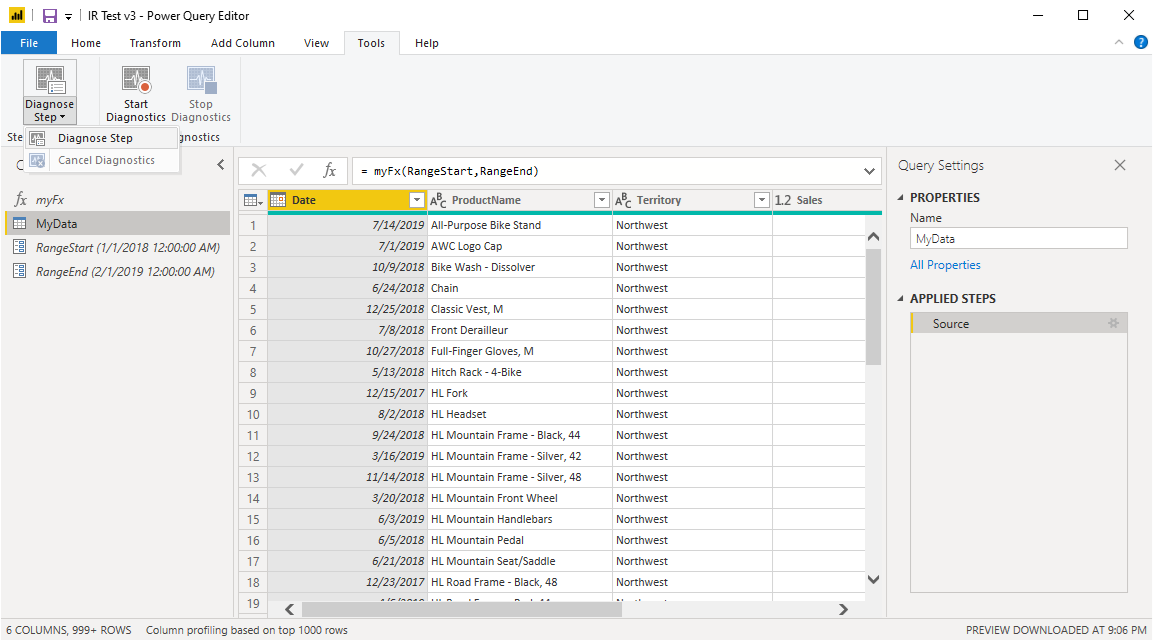
Once you click on it, refresh the query which will create a new set of queries that you’ll see in the queries pane on the left:

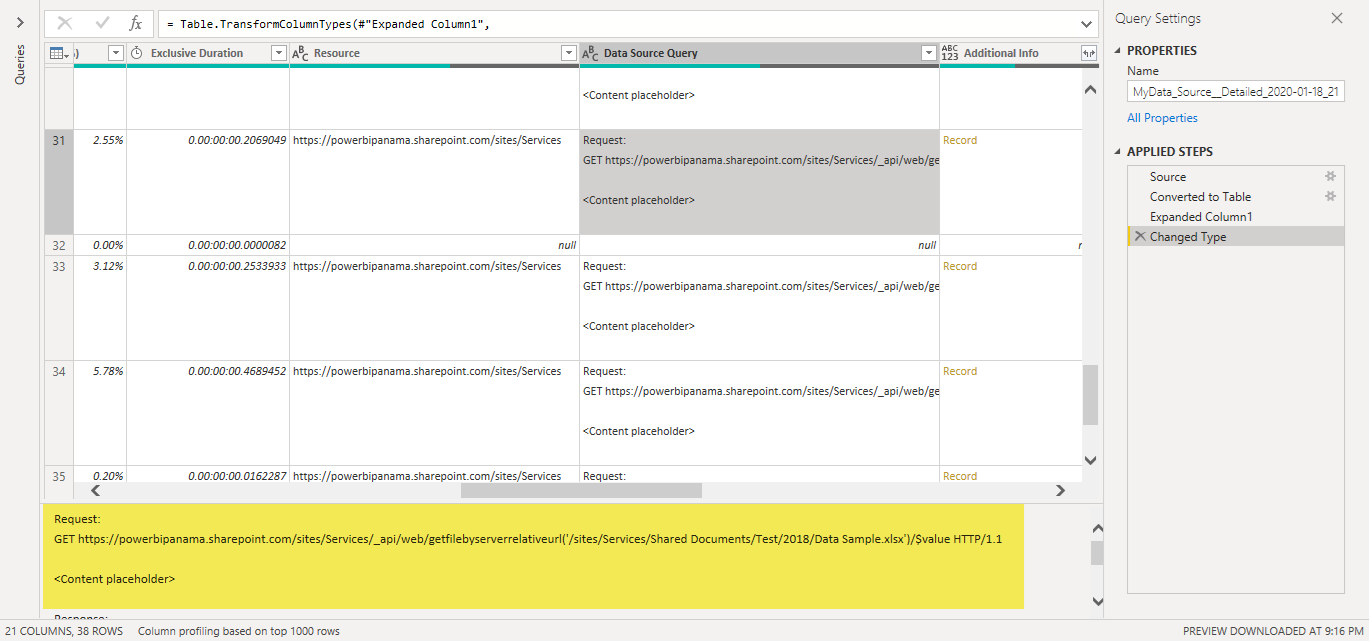
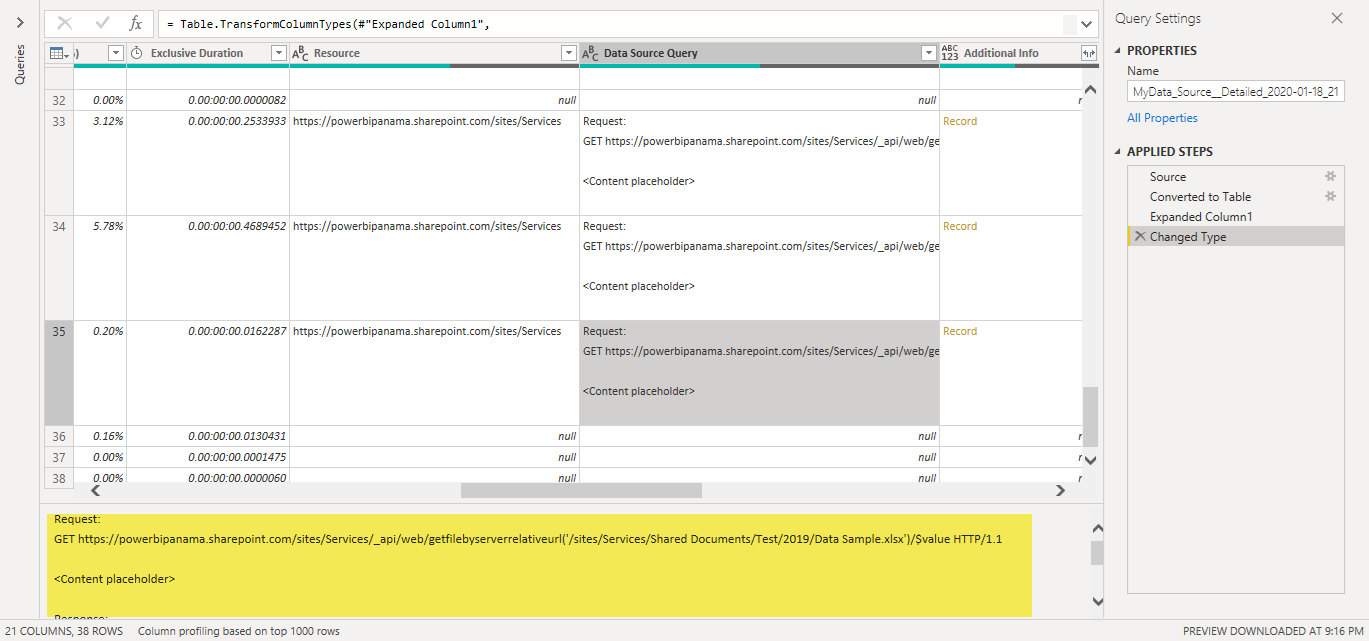
Go to the one that reads “Detailed” in its name. In there, go to the “Data Source Query” field and you’ll see all the calls that were made to the SharePoint API. In my case, I only see that data for the year 2018 and 2019 was requested from the API. Not the one from the year 2020 which is exactly the intended behavior that I was looking for:
For the sake of cleansing, let’s delete all of these new queries that were created by the diagnostics tool and also change the RangeEnd to be today’s date. In my case, I’m writing this blog post on the 18th of January. To me, it looks like this:
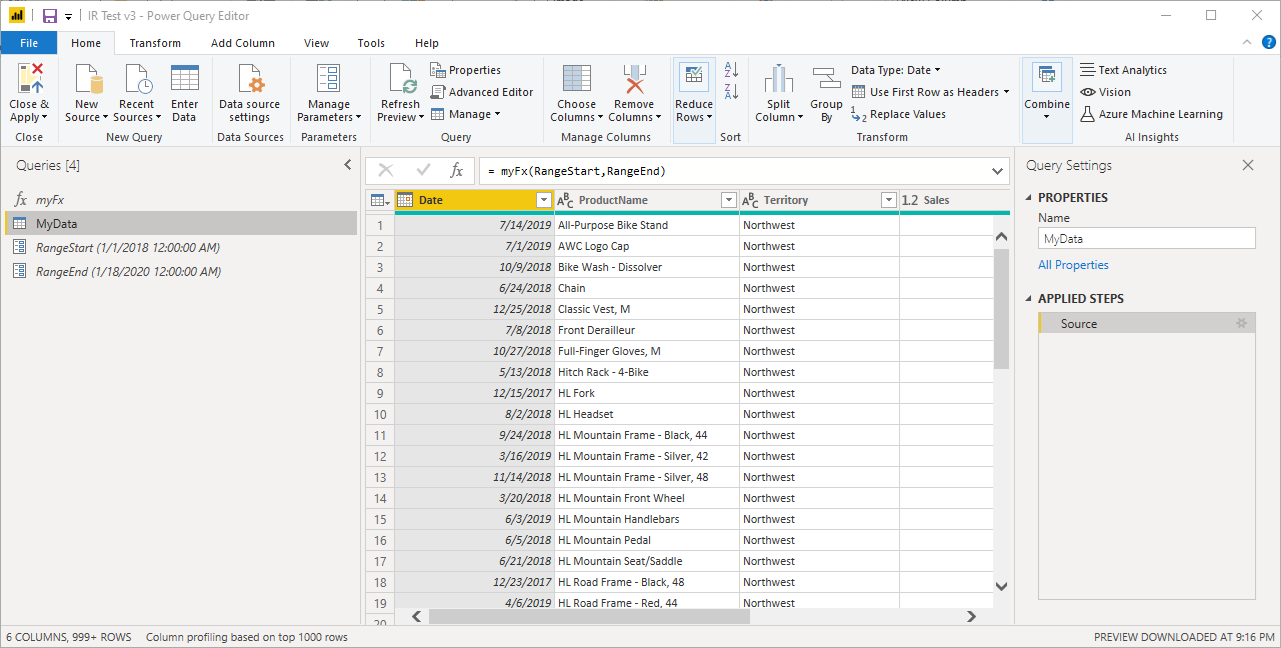
And all you have to do now is just hit “Close and Load” to load your data into your Data Model. This initial refresh will take a while, but we’re just a few steps from having incremental refresh for our files.
Step 4: Set up the Incremental Refresh Policy
Now that our data is in our Data Model, we need to set up the incremental refresh for that specific table / query. Right click on the query and select the incremental refresh option:
Once inside the incremental refresh window, I need to set it up to store only the data for the last 2 years and then only refresh the rows in the last (current) year.
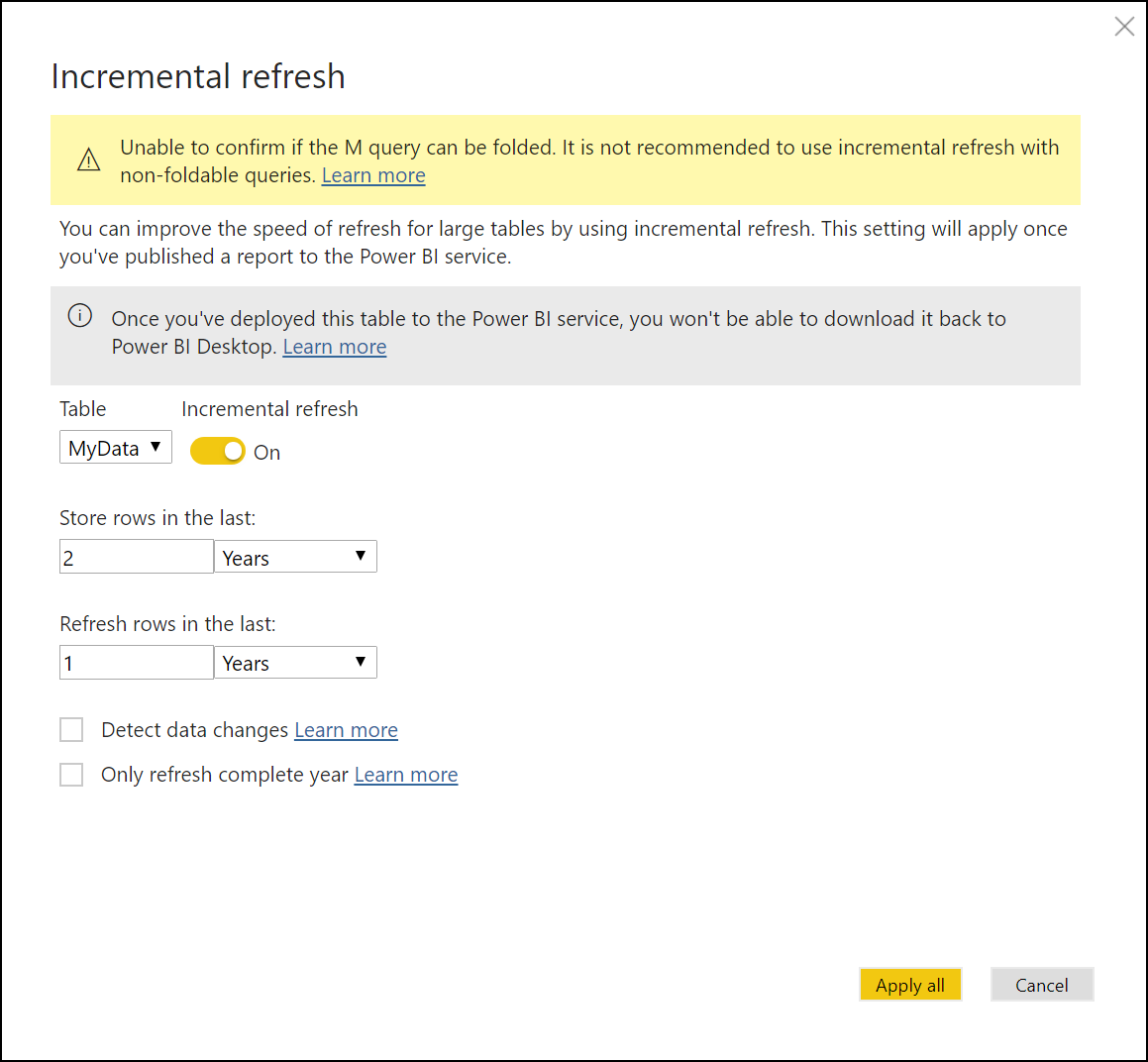
You can absolutely change this and customize it to your needs, but just make sure that you also customize your function and your setup on your folders.
At this point, you’ve finalized everything that has to happen on the Power BI Desktop and you need to now publish your file to the service.
You can follow the steps found on the official Power BI documentation here (url).
Testing our Incremental refresh
Once the file has been published, go ahead and do the initial refresh of the file. I used a pretty small dataset so the refresh took just a few seconds:
The way that I can verify that everything is working as intended is by using the XMLA endpoint for this workspace/dataset and see how the partitions were created.
Checking from SQL Server Management Studio, I can see that all 3 partitions were created:
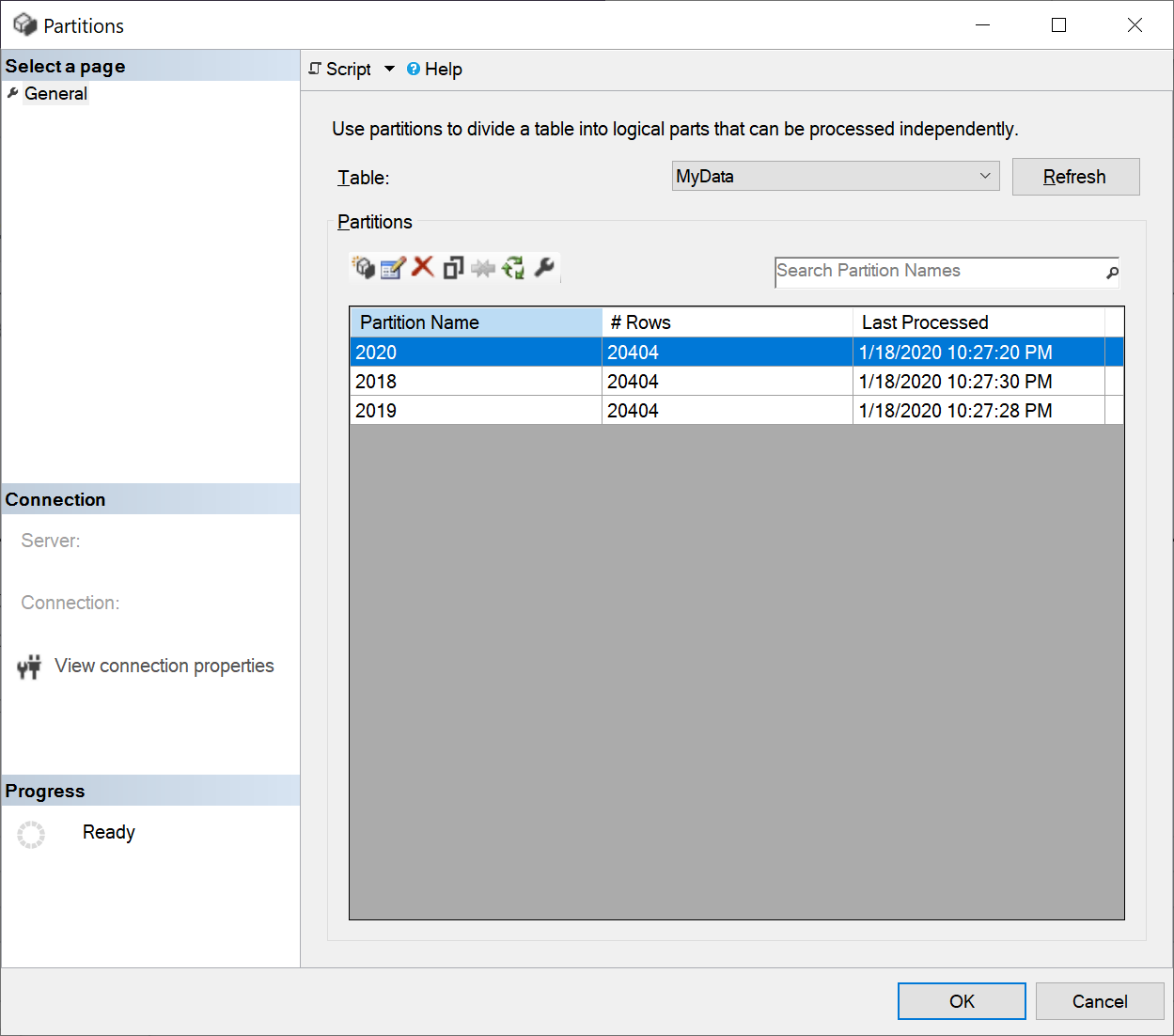
Don’t be fooled by the number of rows. I’m using the same files in each folder, but the column that we should be looking at is the “Last Processed”. That’s how the partitions look after their initial creation.
Now, I waited a few minutes and then refreshsed the dataset a few more times and check how the partitions look now:

IT WORKS!
Check how the values for the partitions on year 2018 and 2019 are exactly the same, but the timestamp for the 2020 partition has changed.
Final thoughts
This pattern can be customized either for a any repository of files such as SharePoint or a local folder.





Does this work under Pro licence or only under Premium?
It should work for Power BI Pro licenses once Microsoft enables incremental refresh of these type of licenses.
That stuff is just great. Thx.
Do I require a premium capacity to make it work?
Currently, incremental refresh is only available for Power BI Premium. Once incremental refresh gets released to Power BI Pro Licenses, then you’ll be able to has with those licenses as well
Hi Miguel,
Do you have the same example using .csv files?
Hey! This pattern should work for any files regardless of what type they are
Hi Miguel,
Is this method should work now on the Power BI pro with February update?
Yes – this shouldn’t have issues working
Hi Miguel,
Query folding is not available for folder data sources (local, SP etc.)
Microsoft warns that incremental refresh without query folding can result in worse performance.
Your example demonstrates how to use incremental refresh against a SP folder and confirms that only the “incremental” data is updated in the model. However without query folding it is still possible (likely ?) that _all_ data is being pulled from the source and then partitioned locally on the server, before updating only the recent partition.
As all data is still being pulled the refresh itself _might_ still run slowly or consume a lot of resource.
Have you actually confirmed that the refresh performance is improved, not just that only the recent data is updated ?
This
https://ideas.powerbi.com/forums/265200-power-bi-ideas/suggestions/15387612-refresh-only-new-data-or-modified-file-in-folder
Hey Andrew,
I highly encourage you to give this scenario a try against SharePoint online so you can test things out. Lazy evaluations are key here, so as long as you know to take advantage of those, query folding is possible with Local Files and the SharePoint API.
You can also use Query diagnostics to see how things are handled in Power BI Desktop and how Query folding is occurring.
Furthermore, The SharePoint connector does have query folding enabled by default as it’s an Odata source – some row level filters are not fully supported, but you could create a custom connector to take advantage of the record metadata such as date modified, date accessed and date created to drive an incremental refresh solution from a SharePoint site. How cool is that?
TLDR; query folding and lazy evaluation are present in the scenario described in this post 🙂 test it out
ah! In regards to the performance, it is quite a noticeable improvement when you’re dealing with dozens of large files as it only refreshes the files that need to be refreshed and not all of them.
The only thing that we can’t take advantage of for Incremental Refresh with files is the usage of a “date modified” field, since we could have that field at the file level, but not at the actual data level.
What are the limits for incremental refresh – for example, I assume incremental refresh only works when the data or transformations for each segment do not cross the file boundaries? If we are tracking lease payments and the files have monthly data, we need to know a start and end date for the lease. If we do a Group By or some other transformation, do we still have to do a full data load so that the proper dates are recorded?
The files themselves don’t have query folding capabilities, but the file storage itself usually does.
Miguel, What abt your forthcoming book. You said earlier that it be out by march 2020. Now march is just round the corner. Is the book finally getting out or still there will be some delay or the idea has been shelved completely. Please do reply.
Hey!
We should be sharing some news about it soon.
Thanks for the question and for checking out the blog post!
PS: I haven’t been posting that many blog posts because of the book 🙂
Regarding SharePoint “Lists”, Can incremental Refresh be performed on a SharePoint Lists, based on the “Modified Date” of an Item (row) in the list?
Not sure. Haven’t tried, but it uses Odata right ? You’ll need to test the query folding to see if it might work for you using that field for filtering
Hi Miguel.
Really well explained articule.
I got a question regarding partitions.
Let´s say my data source have only 3 records, one for 2018, other for 2019 and one more for 2020.
Let´s also say I set incremental refresh policy to store the last 3 years and to refresh only the last year.
Once publish to power bi service, it will create 3 partirions (right?): 2018, 2019 and 2020.
Let´s say the data source change and the 2018 record gets a new time stamp, say, 2019. I run a full refresh in SSMS.
Would happen with the partitions after the full refresh? would it recreate them? (2019 and 2020) or would power bi keep the old ones (2018, 2019 and 2020).
Thanks!
Hey!
Power BI creates a query for each partition. Based on your policy it will create, drop and process the partitions of your choice (last 3 years for example).
The partitions for the last 3 years will be reprocessed.
I’m not entirely sure what you mean by only 3 records or how your query and functions are specified.
The most important part is understanding how partitions work at the Tabular Model level.
Hey Miguel! Thanks for sharing!
I`ve been testing on my side.
It doesn’t seems works on Power BI Pro, I couldn’t verify any timing difference on Scheduled Refresh. Another behavior that see is schema is working on Dataflows and not working on Power BI Desktop Version:2.79.5768.1082 (20.03) (x64).
Do you plan to make some tests using a Pro Account?
I wouldn’t heavily rely on the timing different of the initial load since it’ll just refresh all of the data, but I’d try to get deep into the partition query definition to see if it’s been set up correctly. I can confirm that it’s working on my end and for a number of customers as well where the changes have been dramatic and some of them just use Power BI Pro as well.
In terms of dataflows, incremental refresh is completely different on those to the ones that Power BI has for datasets.
But again, just to confirm, this article applies to incremental refresh in general and is not specific to Power BI Premium.
Thank you! II’ll keep trying.
Just to clarify some points
I’m using Dataflows just to validate the M query.
The first refresh is 20 min, for all other(8 in total) is about the same average.
You should take a look at Chris’ take on how to leverage query folding / lazy evaluation to get the most out of your incremental refresh policies.
https://blog.crossjoin.co.uk/2020/04/13/keep-the-existing-data-in-your-power-bi-dataset-and-add-new-data-to-it-using-incremental-refresh/
The refresh time also relies on how much data you might have and how you’re setting up your incremental refresh policy, so it’s a bit to give you an average or even a good opinion without going deep into your scenario.
It’s probably a better idea to post your situation into the Power BI official forum with all the details necessary to look at it since this comments section can only take a short number of characters and width.
Thanks a lot for the tips and guide. I manage to setup the M code to query on Month folder which stored on my shared drive and have been using it since March. However I notice that the month change to April, it still pointing to month March folder. To troubleshoot this, I manually set the range start and range end on my pbix files to April and it manage to return all files on April. However, once I publish to PB Service, it no longer works. Is there anything wrong with my setup? Could you please help me?
There could be! That’s tough to say. Without looking at your whole core and your full setup, it’s really tough to say.
If you require any assistance we do offer remote consultancy work. You can get in touch with us via email at info@poweredsolutions.co
Hi Miguel,
I took the all PQ Academy courses, I wanted to thank you for that, they are a huge resource. I had a little different scenario I wanted to try that is only refresh from files in a folder that have not already been appended to a data model. In other words I am connecting to a folder as a data source but periodically new files are deposited in that folder so I only want to appended those files that have not been appended before. I figured this maybe possible by running a preliminary query to get all the files in a folder and compare that with a list of unique file names from the data source field in the appended query. The diffculty though is only passing the missing files to the refresh query. Does that seem feasible?
It’s something to explore! Not sure if you can drive this with a refresh policy since that one relies on dates, but it could work depending on how it’s setup
Hi Miguel Escobar,
I implemented the solution you provided and its working great. I’m trying to add FileName as a column, how do I achieve this ?
You’d need to modify your custom function to probably keep them. Probably using the table expand column operation
Figured it out. Thanks!!
I’m trying to implement this solution using Dataflow but seems like Dataflow is looking for column to set up Incremental load, any ideas on how to set it up?
Hey! Incremental refresh on dataflows is a tad different because the data is stored as a csv in the backend inside of a data lake, whereas incremental refresh in power BI datasets you’re basically creating partitions at the Analysis Services Tabular Model level.
I bet that you can accomplish the incremental refresh, but it won’t be as efficient as doing it directly at the dataset level
Great content!
I used this to try and implement a slightly different solution however it is not working 🙁
I am calling a web source (API) and need to have data for the last 1 years. Obviously incremental refresh will be a great option so that I don’t have to pull 12 months of data on every refresh.
I created the RangeStart and RangeEnd parameters, included them in the web url from and to criteria. I had to create a function to deal with pagination as well so I loop the url for each page of data. I enabled the incremental refresh to store data for the 12 months and refresh for the last 3 days. All looked well in the Desktop version after saving and applying (latest May 2020 release). I published it to the service but when I hit refresh it failed with missing column errors. I suspected that for older dates some columns might not have data so I opened the original desktop file again to troubleshoot. Before I changed the RangeStart date to a recent date just so that I don’t pull thousand of record to the desktop version but I couldn’t apply changes, I receive an ODBC error. The only way to fix it was to change the RangeStart and RangeEnd parameter type to Date from Date/Time which broke the incremental refresh functionality and automatically disabled it which enabled me to apply the changes again. I am not sure if this is an issue with the latest May release or if there are underlying issues using this option for a web source. So I have two issues, one the incremental refresh implemented with a web source URL is not working in the service and I am unable to make changes tot he desktop file once incremental updates are turned on.
Hey!
This one might help you: https://www.thepoweruser.com/2018/05/08/first-thoughts-on-power-bi-incremental-refresh/
You need to create a function that yields a fixed schema. That would be the only way
Would you be able to recommend any resources for learning how to actually implement this “fixed schema” approach you mention several times throughout your site? Thanks!
Miguel
I’m still trying to understand and reproduce your approach. I saw on your function you are using StartDate and EndDate as input variables, shouldn’t those inputs be RangeStart and RangeEnd, which are the Incremental Refresh standard parameters?
I also have been trying to figure out how to apply a similar approach but look for “Date Modified” attribute of the files and apply Incremental Refresh policies on those before applying the Table.AddColumn and Table.ExpandTableColumn. Date Modified or Date Created are valuable attributes that should be used by PowerQuery/Dataflow when running this sort of method.
Hey! The name of the function arguments are not dependent on the name of the parameters for the incremental refresh.
The date modified field is something that I’m familiar with, and I had to create a custom connector to make the Correct calls to the SharePoint API.
This is not something that I go in depth in this article as it is a pretty complex and time consuming scenario.
However, this article does give you the general concept to drive the incremental refresh that you might be looking for.
If you need help, we do provide our consultancy services. You can write us for a quote: info@poweredsolutions.co
Muchas Gracias Miguel por la explicación de este artículo! Hice la implementación pero no me funcionó, en Power BI Desktop todo está OK pero al actualizarlo en la WEB todos los valores de mi reporte estaban alterados, el desarrollo fue con una cuenta Pro, el origen de datos es el sharepoint y son archivos csv. Le agradezco si me da algún consejo de como validar en el Servicio si se crearon bien las particiones y que pudo haber ocurrido.
Hola Liyanis!
La principal herramienta es a través del XMLA endpoint para revisar particiones, pero un compañero me compartió lo siguiente para poder revisar las particiones en una cuenta de Power BI Pro:
1. Use Analyze in Excel to get a connection to your model in Excel
2. create a pivottable with a measure in it
3. double click on one of the measure values in your pivottable, this should generate a new sheet with a drillthrough query
4. Then go into the Data menu, click on Connection. You will find a new connection just called “Connection”
5. go into the properties of that and change the command text to SELECT * FROM $SYSTEM.TMSCHEMA_PARTITIONS
Muchas Gracias Miguel!!! Lo haré así y le comento si me funciona. He leído todo sus artículos sobre la actualización incremental y no logro identificar porqué en mi reporte cuando actualizo en Power BI Service los datos se corrompen, en mi caso tengo un modelo dimensional y solo le apliqué a las tablas de hecho la solución que publicó a las tablas de dimensiones no, es decir tengo tablas que le definí actualización incremental y a otras no en mi modelo de datos, podría esto ser el motivo de porqué no me funciona bien al actualizarse? De antemano Muchas Gracias por su respuesta
Hola! Realmente no sabría decirte con certeza la razón detrás de tu situación pues desconozco de cómo lo has planteado, pero realmente lo que ves en este artículo lo he aplicado siempre solo a tablas de hechos sin ningún problema.
Otra herramienta que te puede ayudar a verificar si tus llamadas son las correctas es Fiddler para ver si estás enviando las llamadas correctas al API de SharePoint. Espero esto te sea de ayuda.
Saludos!
Hola
Estoy teniendo problemas para actualizar mis datos que vienen de varios archivos de excel que descargo de un sharepoint y se agregan al final en una base combinada.
He puesto las restricciones de los paremtros en tanto las consultas madres como la consulta combinada, he impedido que se cargue al power bi las consultas madres y solo se estaria actualizado la combinada con las condiciones del incremental refresh. En mi desktop se actualiza muy bien pero en el service me trae el error que no encuentra una columna.
Data source error: {“error”:{“code”:”ModelRefresh_ShortMessage_ProcessingError”,”pbi.error”:{“code”:”ModelRefresh_ShortMessage_ProcessingError”,”parameters”:{},”details”:[{“code”:”Message”,”detail”:{“type”:1,”value”:”The column ‘Sales Quantity’ of the table wasn’t found.”}}],”exceptionCulprit”:1}}}
Alguna idea de que estoy haciendo mal?
Hola!
Realmente esto no tiene que ver con lo que se plantea en el artículo de arriba. Según el error parece que en tu consulta haces referencia a una columna de nombre “Sales Quantity” que simplemente no se encontró en tu fuente de datos (o en el paso donde haces la referencia de dicha columna).
Habría que revisar en detalle pase por pase y refrescar tu vista previa para no trabajar sobre datos pre-almacenados. Así podrías investigar el error y ver porqué sucede.
Saludos y suerte!
I am writing this question for looking some help.
Currently I have add FTP folder (or Local folder) (containing multiple excel files) as my power BI data source under the combine and load option. When running it will combine all the excel files and load to Power BI.
But I am looking to set above for incremental data loading. What I need to do is only load the newly add excel files from last data loading. Finally my Power BI application should have (all last loading data + newly added excel data)
When I search on the internet I saw there are many for direct sources. But I couldn’t find a solution for the non-direct sources such as FTP/excel.
Do you have any idea on above? Could you please help?
hey! The article where you’ve posted this comment (seen above this comments section) should help you with a technique that I created on how to set up an incremental refresh policy for files that are stored in a folder. The technique shown above will work for a folder in a local folder, SharePoint, blob storage, Azure Data Lake Gen2 or even other data sources as long as you follow the same principles and concepts explained in this article
If you do require assistance with the implementation of this technique or perhaps any other inquiries related to Power BI, we do offer remote consultancy. If you’d like to inquire about our services, please reach out to us via email to info@poweredsolutions.co
Best!
Hi Miguel,
thanks for this great idea. What ist the last part of your function for? Why do you have to try if the table.combine works ? Is this a precaution, or neccesary step?
It’s super important that when your query gets evaluated for every partition that the output has the same table schema. However, there might be times when there’s a partition created for a folder that doesn’t exist and this would yield an error – that’s where the try ___ otherwise ____ comes in where if there’s an error then it’ll output the table schema but without any rows.
This is crucial for future-proofing your incremental refresh / partitions policy.
We are now in the midst of going Live with multiple reports for multiple team and we are kind of thinking what’s the best way to implement the logic of incremental refresh within Dataflows when combining historical data ( via sharepoint file) and daily load data via API calls .
Here are some of the key configurations from our side :
a. We are currently on power bi premium subscription
b. We would need to use dataflows (as all transformation logic is stored in dataflows as well) to setup incremental refresh , as this dataflow would be used by multiple reports within individual workspaces catered to end users
c. About data –
a. Historical data : historical (one off activity) data is delivered by our DWH vendor through sftp which we are storing into SharePoint online and pointing our Power BI to this location
b. Our daily data is to be loaded using API calls from our DWH vendor location
c. Key thing to also note is that Daily data is only available on weekdays only (Mon – Fri) So basically run the refresh on Monday to get last friday’s close data
d. Created a dataflow with two entities ( historical and Daily load)
With all the above information – here are some of the things i have tried the below two options and noticed few issues in these . Reaching out to you to hear any better options to set this up .
OPTION 1 – Set Daily refesh for last 4 or 5 days and append to historical table , so last 5 days data is kept updated incase of any backdataed transactions . Append the daily load to Historical load . 1st run works fine , then from Day 2 load – Day 1 data goes missing and Day 4 gets added .
OPTION 2 – Refresh daily load and append to historical table – This option works well but in this case , i would need to pass a date parameter to pick data from DWH for the last Friday’s close and again , if i need to refresh twice a day (AM/ PM ) then this might not work and cause duplicate data when appending to history table
please note – we are using Anonymous connection to connect to Web API
Any help would be appreciated
Hey! I haven’t really attempted to do incremental refresh with Dataflows, but I do know that the mechanism is quite different than the one explained in this article. This article focuses on how to create partitions on your tabular model based on a specific policy using M queries.
I don’t really feel comfortable sharing a suggestion without having a deep understanding of your situation or how the data is structured – especially on incremental refresh with dataflows since I haven’t fully delved into this, but my understanding was that it was meant to be used against relational data sources where query folding can be fully utilized. The article that I wrote primarily takes advantage of Lazy Evaluation and not really Query Folding as SharePoint is not a super foldable data source for what we’re trying to accomplish.
I’d recommend that you post your full scenario with lots of details on the official Power BI Dataflows forum:
https://community.powerbi.com/t5/Power-Query/bd-p/power-bi-services
Got a question on incremental refresh. Currently set it up and published. However the file refreshes every hour based on one drive refresh. One drive refresh was set up before I did the incremental refresh setup on the query. Will the incremental refresh still work even with a one drive refresh?
Hey!
I’ve never actually tried that before. Usually what I do is that I create a dataset with the incremental refresh so it has all the correct partitions and everything and then I connect to that dataset using Power BI Desktop dataset live connect so that I don’t have the full data model AND the report in the same file.
The way that incremental refresh works is that it creates a set of partitions on your data model so that your full data model lives completely on the Power BI Service. If there’s something that constantly tries to overwrite the previous data model and its own partitions (like the OneDrive Sync), then I can see that as a conflict.
I’d recommend that you reach out to the Power BI Support team to check with them, but I’ve never attempted this and don’t recommend it either.
Am I missing some information here?
The only code I see for step 1 is one line highlighted in yellow and beginning #”Filtered Rows” =
Hey!
Could it be that your firewall is blocking the embedded Github code? Here’s the direct link to that embedded script:
https://gist.github.com/migueesc123/4f9986d9f4945a5cb8f1c0e17cda2f0c#file-incremental-refresh-yearly-sp
Hello, Somehow the custom function is not visible now. It was previously. Can you please help post it so that we can look to carry the steps
hey! thanks for reporting this. I’m not sure what happened, but i’ve changed this from being an embedded iframe from github to just being pure text.
How can i have and incremental refresh on sharepoint file online folders?
hey! the article above explains the core concepts on how to accomplish that. Do you have any specific questions around the article?
Muchas gracias Miguel, tengo estas dudas por favor, segun la imagen del PBI se archiva la informacion desde 12/18/2019 hasta el 12/18/2020; desde este fecha 12/18/2020 inicia el Incremental Refresh hasta el 12/18/2021; he cambiado datos en diferentes meses para comprobar el refresh, pero no he tenido exito en la manera de comprobarlo, que me recomiendas, soy muy nuevo con el tema del SQL-SMS. Losarchvos los tengo en Local no en SP.
Hi Miguel,
Very clear article.
I would like to try and do something different, but not sure if it is possible.
On my production database, I have a field LAST_UPDATED_AT that is updated via a trigger every time the record is updated.
I would like to have a daily sharepoint file with ONLY the changes to any of the data records. So, on a daily basis, I have a process that finds the records that has changed in my production database, and extract the data to the file, only the records that were changes since yesterday.
In this mode the file is always the same file (name), and we just need to load these records (either new or updated).
Is that possible ? how ?
Thanks Roni.
Hey!
Not possible to have query folding or lazy evaluation against a file. (unless it’s parquet I believe)
The article primary tackles how to take advantage of lazy evaluation when you connect to a folder or any of the connectors that use the “file system view” like Azure Data Lake, SharePoint, Folder, Blob storage and others.
You may want to also post this question on the official Power BI Community Forum in case there might be other feedback from other folks.
Best!
Thanks.
So no option to just add more records ? everytime you load a file it will replace all the records in that partition (in a way it make sense, as it takes care of deleted and updated record at the same time, but the performance can’t be good).
It can be done if I will create a database (MySql or others) and store all the records in that database (so upload to this DB just the delta records, but the DB itself will have all the records), right ?
Thanks for all the help,
The best option would be to use a connector that has query folding capabilities to take advantage of them. SQL Server or other connectors offer you the capabilities that you need.
I’d recommend that you check out the articles from the links below to better understand how the evaluation works in Power Query:
Understanding query evaluation and query folding in Power Query – Power Query | Microsoft Docs
Query folding examples in Power Query – Power Query | Microsoft Docs
Best!
That was amazing. I tried to implement it and I already see significant improvements in refresh time in Power BI desktop. When I publish the report to the service however, if the Incremental Refresh is configured, I can not refresh it online even once. I get an error saying “The ‘<pii>Column1</pii>’ column does not exist in the rowset”. I tried a couple of times and it throws out the error about different columns of my table. The thing is I can see those columns in the table in Power BI desktop.
I also see that my dataset has only 1 partition.
Any ideas?
Hey!
Hard to say. You’d need to step into the code to see exactly which partition is giving you that error and why. It could be that one of the partitions tries to find that column but it simply doesn’t find it (for whatever reason that might be going from a folder with no files, incorrect files, incorrect naming convention, etc etc etc).
Hi, I get the exact same behavior once published, tells me that my first column is missing with same error message despite all files respect the same schema and all runs fine without incremental activated. I can confirm this was working fine previously, had used the method earlier in 2021.
Maybe some regression due to evolution on the way incremental refresh is managed in the service.
Supercool! Thanks!
One question: What if I change a file in the “past” year’s folder and need to refresh everything again once. Is this possible in the service? Or do I need to refresh everything in the desktop?
you should be able to access the partitions of your tabular model (dataset) and reevaluate them if needed.
Can I combine 2 data sources: SQL and Sharepoint Folder and still implement the scheduled refresh?
it depends! hard to say as it really depends on how you extract data from those sources and how you combine them. Under specific circumstances, it should be possible
Hi , am using Shaepoint files as datasource. created two main table and one append table with those main tables.
1. when i apply incremental refresh on main table do i need to apply incremental refresh on append table as well???
2.when i apply incremental refresh on append table , will append table refer data from main tables or it refer sharepoint to load the data.
Hey!
It really depends on how you’re getting those two main tables. Difficult to say really. It would require a full analysis of your queries and see what data is being called to your SharePoint site through a tool like fiddler to see if incremental refresh is actually happening or not (or more in the sense if things are being lazily evaluated to only the folders that you want to get the data from)
Hello Miguel,
first of all thanks for sharing your knowledge.
I wanted to ask two questions:
Thanks for your help
Hey! Table.Combine doesn’t require you to pass the name of the columns that you want in your output table whilst Table.ExpandTableColumn requires it.
If you have an outter field that you want to pass to a value inside of the cells, you could transform the tables inside of a column to have a new field (using something like Table.AddColumn) so you add that value as you wish. You could also create a custom function to tackle it that way, but there’s really no other way.
At that point it becomes more of a question on how you wish to strategically tackle your scenario and what is best for your specific scenario. There could be multiple approaches and perhaps the most effective one or easiest one for your scenario might not be a Table.Combine
Hi
•I will be receiving a file added in a FOLDER every day.
•As soon this file is added, I would like to visualise in power bi if it is added.
•Like this I have 10 FOLDERS where a file gets added each day. These files can be anything from zip file, raw data file, csv file, some unknown format.
•I do not want to process data in these files but just want to an update at of the day that how many of these FOLDERS have received a file.
•These folders can email folder or SharePoint folder.
•If a file is not received for consecutive two days, I would like to receive a email reminder.
Can you suggest a method to setup this if it is possible?
Hey!
i’d recommend posting this on the Power BI Community forum since it would be the best way to see multiple alternatives. This comment section would fall short in trying to explain how to implement a solution to address those requirements. Below is the link to the community forum:
https://community.fabric.microsoft.com/t5/Get-Help-with-Power-BI/ct-p/PBI_GetHelp