 Miguel Escobar Publicada febrero 7, 2021
Miguel Escobar Publicada febrero 7, 2021 
Hace unos días estaba revisando las redes sociales para encontrar casos interesantes en los que Power Query podría ser una buena solución. Encontré este escenario publicado por Brian en un grupo de Facebook aquí (url).
Imagine un escenario en el que tiene una columna con valores de texto, pero dentro de cada cadena de texto hay duplicados.
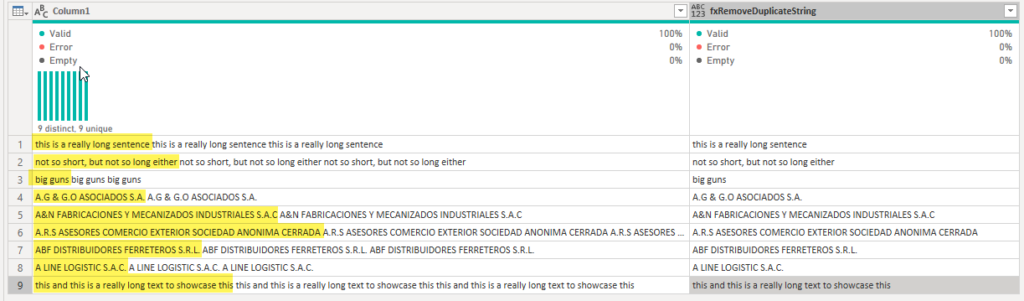
Tome la imagen anterior donde desde Column1 queremos:
- Encontrar la subcadena que se repite en la celda
- Eliminar los duplicados y conservar solo una instancia de la subcadena que se repite
Efectivamente, lo que necesitamos es lo que ves en la columna de nombre fxRemoveDuplicateString.
En términos más claros, si tenemos un valor como:
this is a really long sentence this is a really long sentence this is a really long sentence this is a really long sentence
Luego queremos pasar esa cadena de texto a través de una función que debería generar solo la subcadena que se repite y comienza desde la posición cero:
this is a really long sentence
La función que hace la magia
Nota: La siguiente sección mostrará una gran cantidad de contenido avanzado en lenguaje M.
Primero me gustaría compartir la función personalizada que he creado para resolver este escenario y luego iré paso a paso sobre lo que hace y por qué:
La función hace exactamente lo que necesitamos. Intenta encontrar la subcadena que se repite y, una vez que encuentra el mejor candidato, elimina los duplicados y conserva esa única instancia.
Al principio intenté utilizar la opción Columna a partir de ejemplos (url) en Power Query, pero esto no produjo el resultado que esperaba, así que tuve que crear mi propia función personalizada.
Pasemos a la función para ver cómo funciona y por qué. Puedes descargar el archivo de muestra desde el botón de descarga a continuación:
Combinations
= List.Transform( {1.. Text.Length(Sample_Text)}, each Text.Start( Sample_Text,_))
El primer paso de la función es obtener el total de caracteres en las cadenas. Es por eso que uso la función Text.Length contra Sample_Text. Una vez que tengo ese valor, creo una lista con la misma longitud que el total de caracteres en el valor del texto.
Para mi ejemplo, estoy utiliznado el texto this is a really long sentence this is a really long sentence this is a really long sentence como mi texto de ejemplo (Sample_Text). Este tiene una longitud de 92 caracteres, creo una lista de 92 elementos con los valores del 1 al 92.
Luego reviso cada elemento en esa lista y aplico la función Text.Start que me trae solo la cadena de texto, pero corta la misma por la cantidad de caracteres que paso en el segundo argumento de la función que resulta ser el elemento de ese lista que se pasa como argumento de la función.
Como sabemos que el inicio de la cadena siempre comenzará desde el primer carácter, la mejor idea que se me ocurrió fue crear esta lista de posibles subcadenas y luego probar cada una hasta encontrar la que se ajusta a nuestra lógica. Es por eso que el primer paso simplemente crea esta lista de subcadenas potenciales o posibles que podrían convertirse en la salida de esta función.
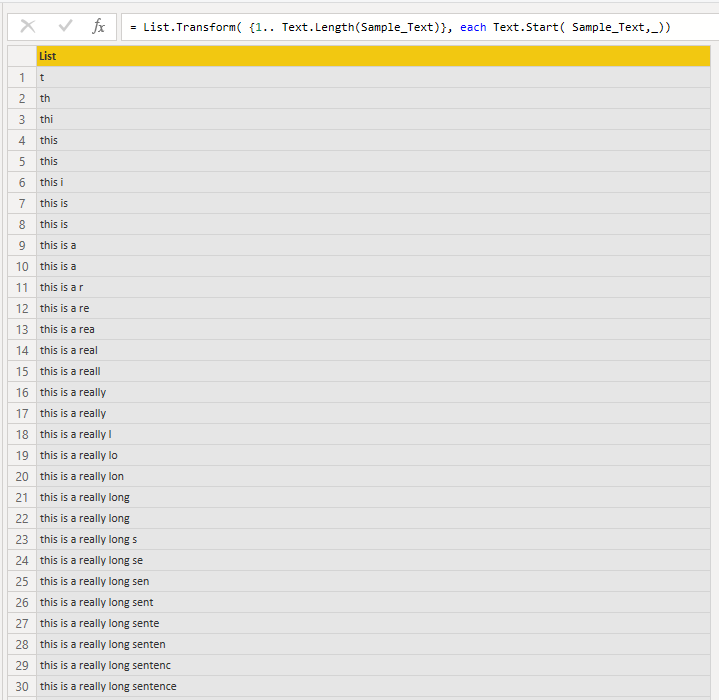
Iterations and Total_Iterations
Este es el paso donde ocurre la magia. Conceptualmente, lo que está haciendo este paso es un ciclo while en el que voy elemento por elemento de la lista de Combinaciones para probar cuál tendría la mayor probabilidad de ser el que se está duplicando. Todavía estoy tratando de optimizar este paso ya que solo tuve alrededor de 40 minutos para llegar y probar esta solución, pero hasta ahora se ve bien a nivel conceptual.
El resultado de este paso es simplemente una lista con N elementos que luego cuento en el paso Total_Iterations.
Filtered_Possible_List
= List.Transform( Combinations, each Text.Split(Sample_Text, _){Total_Iterations})
El objetivo de la iteración anterior era lograr una lista que comenzara a darme errores y un elemento en la lista que tuviera un valor nulo, en blanco o vacío como se puede ver en la fila 30 de la imagen a continuación:
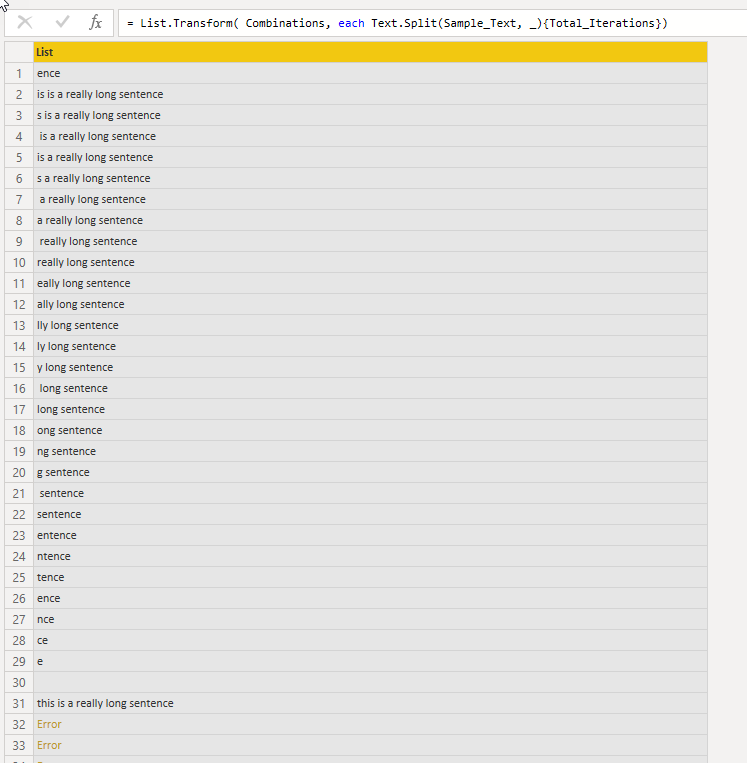
La razón por la que estoy tratando de encontrar la primera iteración que comienza a darme errores a nivel de lista es porque esto me dice que esos errores no son buenos candidatos ya que no se repiten tanto como el resto.
Table_From_Possible
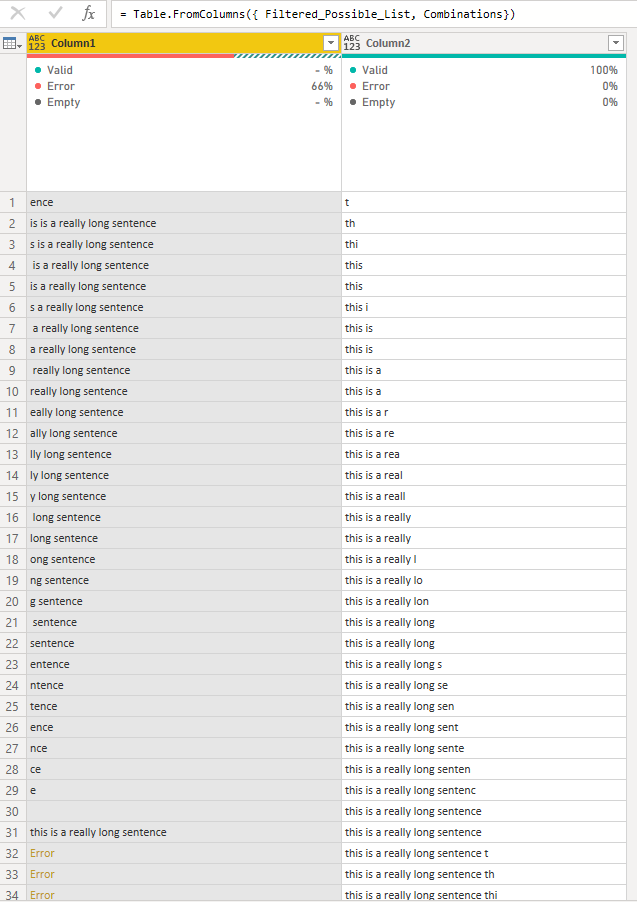
Luego creo una nueva tabla a partir de Filtered_Possible_List y las listas de Combinaciones usando la función Table.FromColumns.
= Table.FromColumns({ Filtered_Possible_List, Combinations})
Y es entonces cuando las cosas empiezan a tener más sentido visualmente.
Removed Errors
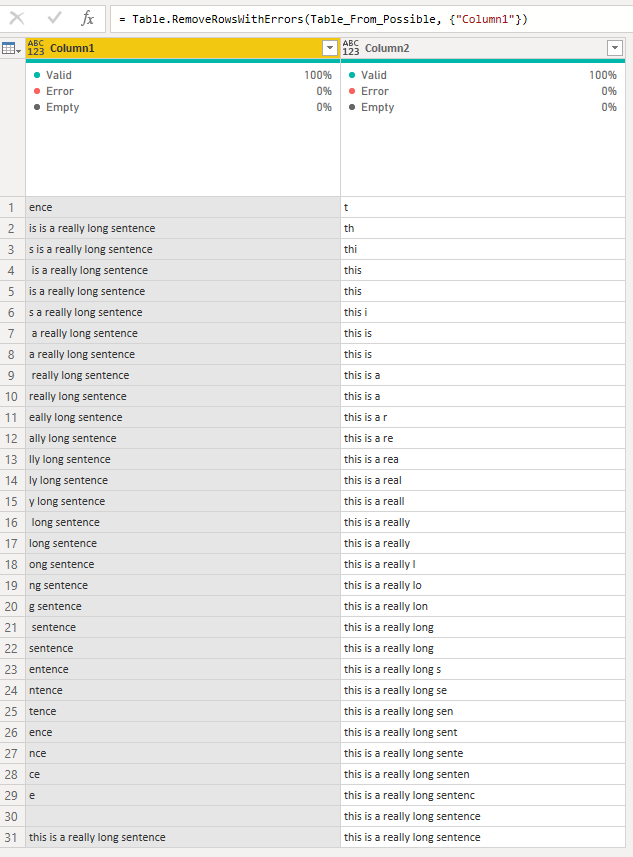
En este paso, simplemente elimino los errores del campo con el nombre Column1.
Filtered rows
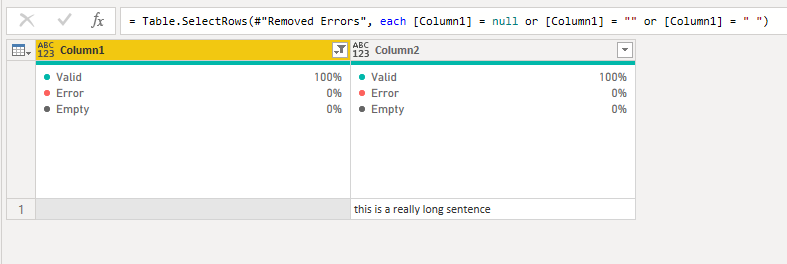
Luego filtro la tabla usando los valores del campo con el nombre Columna1 para mantener solo los valores que son nulos, vacíos o con un espacio en blanco. Estas filas son efectivamente las mejores candidatas, ya que eran las que tenían una coincidencia perfecta o casi perfecta para la subcadena.
Kept Last Rows and Custom3
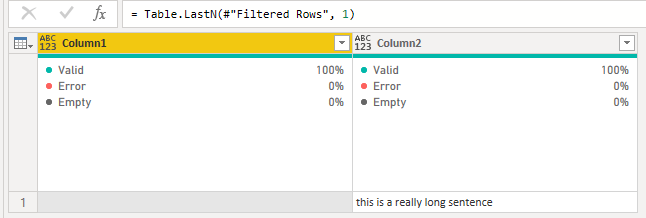
En algunos casos, puedo terminar con varios candidatos, así que agregué este paso para elegir siempre la última fila de la tabla que, en teoría, siempre debería ser la cadena más larga o la cadena con la mayoría de los caracteres:
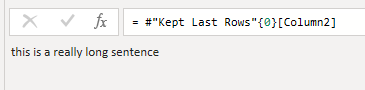
Y el último paso de la función, llamado Custom3, simplemente navega a la celda que contiene la cadena que necesitamos y ese paso es la salida de la función:
Conclusión
Esto fue un escenario bastante interesante y uno que no puedo averiguar cómo resolver sin usar algún tipo de bucle while o algún tipo de función recursiva. Hay mucho margen de mejora con esta función y espero hacer esas mejoras más adelante.
Publica tus comentarios en la sección siguiente y avíseme si tiene otros escenarios interesantes que pueda abordar.





La fórmula no me funcionó 🙁
Hola!
Acabo de probar la función y parece funcionar. No sabría decirte qué podría estar sucediendo, pues no tengo acceso a tus datos o al mensaje de error.
Te sugiero publicar la consulta en el foro oficial de Power BI en español pues tal vez tu caso podría necesitar algunos cambios a nivel de la función:
https://community.powerbi.com/t5/Translated-Spanish-Desktop/bd-p/pbi_spanish_desktop
Saludos!